
Chatbot Statistics
As per https://startupbonsai.com/chatbot-statistics/, Gartner predicted that by 2022, 70% of white-collar workers will interact with some form of chatbot by 2022.

Customers like chatbots because they give quick responses.
Although I like Cool Technology.

Chatbot uses in Customer Support
Chatbots are used in customer support for the following reasons:
- First line customer support to know to which representative we need to direct the customer call.
- To collect customer feedback.
- Help in order confirmation & track shipping.
What is RASA NLU?

Rasa NLU (Natural Language Understanding) is an open source natural language processing tool to convert messages from users into intents and entities that chatbots understand.
What is Intent ?
Rasa uses the concept of intents to describe how user messages should be categorised. Rasa NLU will classify the user messages into one or also multiple user intents.
What is Entity?
Entities are structured pieces of information inside a user message. When deciding which entities you need to extract, think about what information your assistant needs for its user goals.
Intent Entity example
Let’s look at an example of “I want to buy air tickets from Bangalore to Delhi”
We can understand a few basic things:
- The person is interested in buying air tickets. (intent)
- Source city is Bengaluru (entity)
- Destination City is Delhi.(entity)
As you can see that buying air tickets is the intent. Source and Destination Cities are the entities. They are the basic building blocks for most queries.
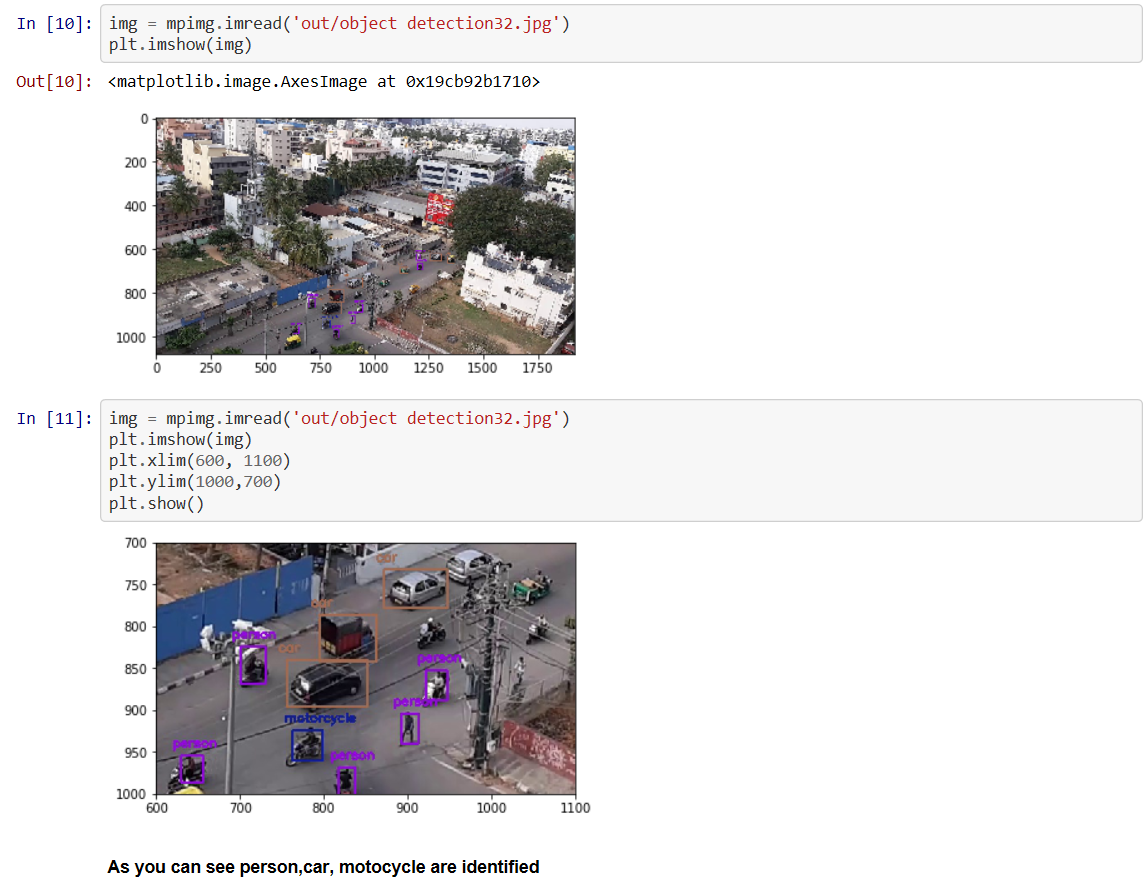
Some Theory
I have collected a few RASA NLU design pictures to explain how it works they say “A picture is worth a thousand words”. Images given below are from https://rasa.com/blog/intents-entities-understanding-the-rasa-nlu-pipeline/ and https://rasa.com/blog/bending-the-ml-pipeline-in-rasa-3-0/
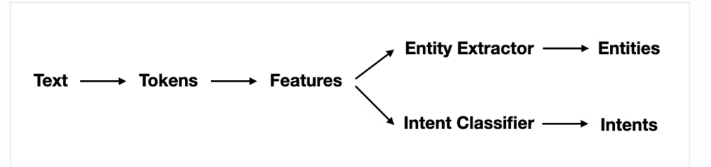
RASA Pipeline for 2.x versions
RASA NLU Core Pipeline is as shown below
RASA 3.0 — NLU and Core Pipelines
Their design has changed. This is RASA 3.0 Pipeline with DIET classifier.

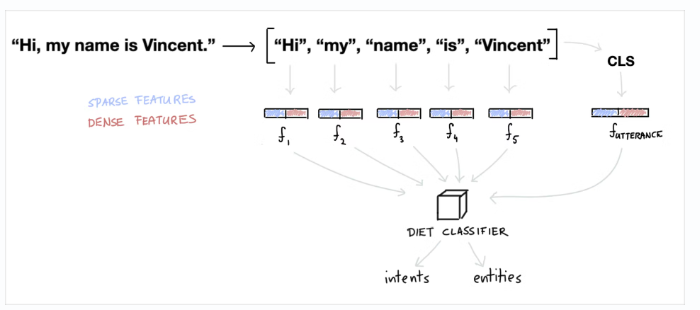
Tokenization and Lemmatization

Features
Image is from https://rasa.com/blog/intents-entities-understanding-the-rasa-nlu-pipeline/

Intent Classifiers
Image from https://rasa.com/blog/intents-entities-understanding-the-rasa-nlu-pipeline/
What is a Story?
Stories are used to teach Rasa real conversation designs to learn from providing the basis for a scalable machine learning dialogue management.
Creating A Simple Chatbot
Let us create a bot. For simplicity we will just ask a question and let the bot reply “Found intent <intent name>”.
Train questions from Quora kaggle dataset
Let’s create a bot that replies to the following three questions
- What are the differences between clients and servers?
- What is the difference between a server and a database?
- How can I become a data scientist?
I have taken these questions from https://www.kaggle.com/c/quora-question-pairs
Initial Steps
Initialize chatbot as shown below in a fresh directory
$ pip3 install rasa
$ rasa init -v — init-dir /tmp/mybot
Manually Modify domain.xml, data/stories.yml, data/rules.yml and data/nlu.yml
In file data/nlu.yml : Add Intents
Add each question in one intent. We can add multiple questions also in one intent if the have the same meaning but are structured in a different way.

In file data/stories.yml add stories
In this example we have taken single question and answer story. We can add multiple sequential questions and answers also in a story. Add intents and actions in each story as shown below.

In file domain.yml : add intents and responses
Add intents and responses in domain.yaml as shown below

Final Steps
Validate the files we have modified above. Train a model and start interacting with the rasa shell.

Test Using Full Sentences
When I type the sentences, it is able to identify the intent as expected.
Pink color ones are the words I typed and purple color lines are the replies.

Test using just words
When I give individual words, it is able to identify the intent even with the words

All the files which I used in the demo are available in my github repository here.

























































{kind=link}
{kind=link}